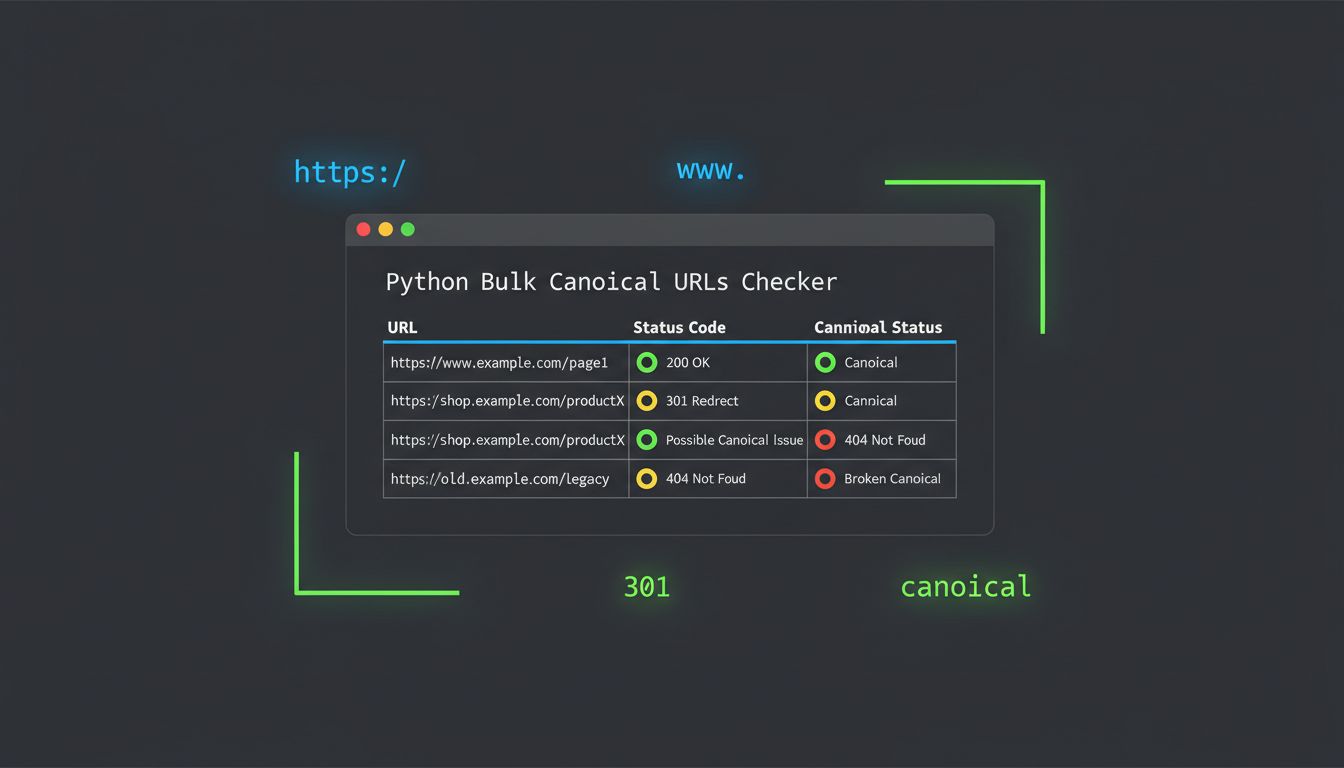
Build a Canonical URL Checker in Python to Audit Any Domain List – Canonical URLs are one of those SEO fundamentals that sound simple until your site starts bleeding rankings and you have no idea why. The concept itself is not complicated: you tell search engines which version of a URL is the “real” one.
But the execution? That is where it gets messy.
Is it https://example.com or https://www.example.com? Does your HTTP version quietly serve a duplicate page instead of redirecting?
Is your <link rel="canonical"> tag pointing somewhere it should not?
Any one of these misconfigured, and Google is happily indexing two versions of the same content, splitting your link equity, and quietly punishing your rankings while you wonder why your traffic graph looks like a ski slope.
Checking one domain manually is annoying. Checking fifty is a special kind of torture.
This post walks through a Python script that automates the whole thing: it reads a list of domains from a file, checks all four URL variants (HTTP/HTTPS combined with www/non-www), follows redirect chains, parses <link rel="canonical"> tags from the live pages, and returns a verdict with a confidence level for each domain.
The results go to the terminal in color-coded output, and to both a CSV and a plain text file for reporting or further processing.
TLDR
Hide- The script checks all four URL variants per domain (HTTPS/HTTP combined with www/non-www), follows redirect chains, and parses
<link rel="canonical">tags, giving you a complete canonical picture for each domain in a single automated pass. - Canonical verdicts are assigned a confidence level:
highwhen a consistent canonical tag or full redirect convergence is found,mediumwhen signals conflict, andlowwhen the site has serious configuration problems that need immediate attention. - The highest-priority canonical signal is a consistent
<link rel="canonical">tag across all working variants. Redirect convergence to a single HTTPS URL is the next best signal. Both www and non-www returning 200 independently, with no redirect between them, is flagged as a duplicate content risk. - HTTP variants that do not redirect to HTTPS, redirect chains longer than three hops, and www/non-www variants resolving to different hostnames are all detected and reported as separate issues per domain.
- Output goes to three places simultaneously: a color-coded terminal display, a CSV file with full per-variant data for spreadsheet analysis, and a plain text file containing one canonical URL per line for use in other scripts or pipelines.
- The script is designed for easy extension: adding concurrency with
ThreadPoolExecutor, integrating with XML sitemap parsing, or wrappingcheck_domain()as a FastAPI endpoint are all low-friction paths to a more powerful audit tool. - Running it requires only
requestsas an external dependency. Everything else is Python standard library, making setup a singlepip installaway.
No paid tools, no browser plugins, no clicking through dozens of tabs. Just Python and a list of domains.
What Are Canonical URLs and Why Should You Care
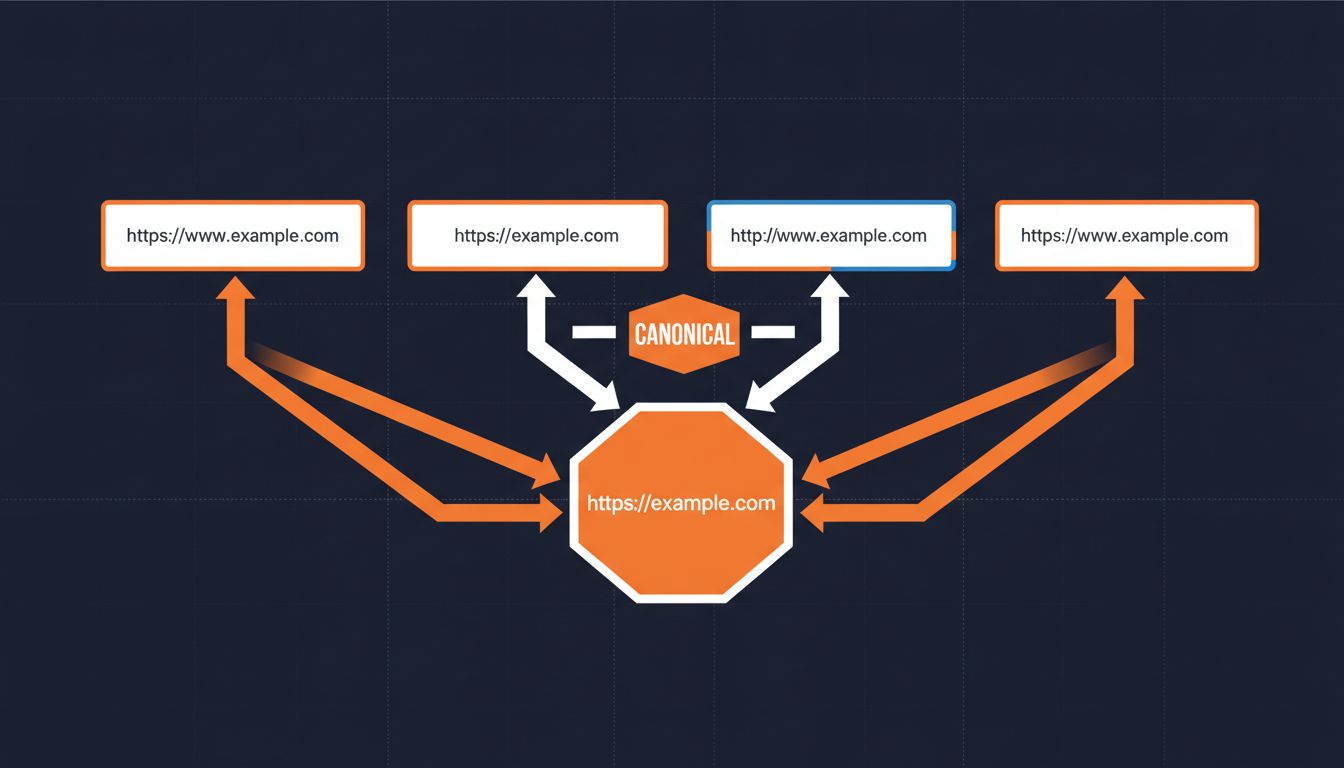
A canonical URL is the single, authoritative version of a page that you want search engines to index and rank. When the same content is accessible at multiple URLs, canonical tags are how you tell crawlers to ignore the duplicates and focus on the original.
Get it right and your ranking signals consolidate on one URL.
Get it wrong and you have a duplicate content problem, which is one of the quieter, harder-to-diagnose SEO issues you can encounter.
The most common canonical mistakes are also the most boring: the www and non-www versions of a domain both serving live pages without redirecting to each other, HTTP not redirecting to HTTPS, or a canonical tag that points to a different URL than the one that actually loads.
These issues are easy to miss when you are only checking one site.
When you are auditing a portfolio of sites, a competitor list, or a client roster, you need automation.
The script covered in this post checks all of those things in one pass. It is not doing anything magical.
It is just doing methodically what you would do manually, just without the tedium.
Python Bulk Canonical URLs Checker Overview: What It Checks and How

Before going line by line, here is what the script actually does at a high level.
For each domain in your input file, it constructs four URL variants: https://example.com, https://www.example.com, http://example.com, and http://www.example.com.
It fetches all four, follows any redirects, records the final landing URL and HTTP status code for each, and extracts any <link rel="canonical"> tag from the page HTML.
It then runs a heuristic called determine_canonical() that applies a priority-ordered set of rules to decide which URL is the true canonical, assigns a confidence level (high, medium, or low), and lists any issues it found. The final verdict per domain gets printed to the terminal and written to output files.
The whole thing runs from the command line with a few optional arguments for input file, output files, timeout, and delay between requests.
Setting Up: Requirements and Installation
The script uses only two external dependencies: requests for HTTP calls and Python’s standard library for everything else. If you are not already working inside a virtual environment, now is a good time to create one.
The Python virtual environment guide covers the setup across Windows, Linux, and macOS if you need a refresher.
Install requests:
pip install requests
That is the entire dependency list. urllib.parse, html.parser, csv, argparse, sys, and time are all part of the standard library.
Create an input file called url.txt in the same directory as the script. Add one domain per line.
No need for protocol prefixes, the script normalizes them:
example.com
www.mysite.org
anotherdomain.net
# Lines starting with # are treated as comments and skipped
Full Script
#!/usr/bin/env python3
"""
Canonical URL Checker
Checks www vs non-www, HTTP vs HTTPS, redirect chains, and <link rel="canonical"> tags
for a list of domains from url.txt (one domain per line).
Usage:
python check_canonical.py
python check_canonical.py --input my_domains.txt --output results.csv --timeout 10
"""
import sys
import csv
import time
import argparse
import requests
from urllib.parse import urlparse
from html.parser import HTMLParser
# ── Canonical tag parser ────────────────────────────────────────────────────
class CanonicalParser(HTMLParser):
"""Extract <link rel="canonical" href="..."> from HTML."""
def __init__(self):
super().__init__()
self.canonical = None
def handle_starttag(self, tag, attrs):
if tag == "link":
attr_dict = dict(attrs)
if attr_dict.get("rel", "").lower() == "canonical":
self.canonical = attr_dict.get("href")
# ── Core checker ────────────────────────────────────────────────────────────
HEADERS = {
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/124.0.0.0 Safari/537.36"
),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.5",
}
def normalize_domain(raw: str) -> str:
"""Strip protocol and trailing slash, return bare domain."""
raw = raw.strip()
if "://" in raw:
raw = raw.split("://", 1)
return raw.rstrip("/")
def fetch(url: str, timeout: int, session: requests.Session):
"""
Fetch a URL, following redirects.
Returns (final_url, status_code, redirect_chain, canonical_tag, error).
"""
try:
resp = session.get(url, timeout=timeout, headers=HEADERS, allow_redirects=True)
chain = [r.url for r in resp.history] + [resp.url]
# Parse canonical tag from the final page
parser = CanonicalParser()
try:
parser.feed(resp.text[:50_000]) # only scan the first 50 KB
except Exception:
pass
return resp.url, resp.status_code, chain, parser.canonical, None
except requests.exceptions.SSLError as e:
return None, None, [], None, f"SSL error: {e}"
except requests.exceptions.ConnectionError as e:
return None, None, [], None, f"Connection error: {e}"
except requests.exceptions.Timeout:
return None, None, [], None, "Timeout"
except Exception as e:
return None, None, [], None, str(e)
def check_domain(domain: str, timeout: int, session: requests.Session) -> dict:
"""
Check all four variants (http/https × www/non-www) and determine the canonical URL.
"""
bare = normalize_domain(domain)
has_www = bare.startswith("www.")
non_www = bare[4:] if has_www else bare
www_ver = "www." + non_www
variants = {
"https_non_www": f"https://{non_www}",
"https_www": f"https://{www_ver}",
"http_non_www": f"http://{non_www}",
"http_www": f"http://{www_ver}",
}
results = {}
for key, url in variants.items():
final, code, chain, canonical_tag, error = fetch(url, timeout, session)
results[key] = {
"url": url,
"final_url": final,
"status_code": code,
"redirect_chain": chain,
"canonical_tag": canonical_tag,
"error": error,
"redirects": len(chain) - 1 if chain else 0,
}
# Small delay between requests to be polite
time.sleep(0.3)
# ── Determine canonical verdict ─────────────────────────────────────────
verdict = determine_canonical(domain, results)
return {"domain": domain, "variants": results, "verdict": verdict}
def determine_canonical(domain: str, results: dict) -> dict:
"""
Apply heuristics to decide the true canonical URL.
Priority order:
1. <link rel="canonical"> tag on the final page (highest trust)
2. HTTPS over HTTP
3. If both www and non-www land on the same final URL -> that IS the canonical
4. Redirect target preferred over origin
5. Flag if both are live and independent (no redirect between them)
"""
https_nwww = results["https_non_www"]
https_www = results["https_www"]
http_nwww = results["http_non_www"]
http_www = results["http_www"]
# Collect successful HTTPS results
https_variants = {k: v for k, v in results.items()
if k.startswith("https") and v["status_code"] == 200}
# Collect any working variant
working = {k: v for k, v in results.items() if v["status_code"] == 200}
issues = []
canonical_url = None
confidence = "unknown"
# 1. <link rel="canonical"> tag — highest authority
canonical_tags = {v["canonical_tag"] for v in working.values()
if v["canonical_tag"]}
if len(canonical_tags) == 1:
canonical_url = canonical_tags.pop()
confidence = "high"
issues.append("Canonical tag present and consistent.")
elif len(canonical_tags) > 1:
canonical_url = list(canonical_tags) # just pick one
confidence = "low"
issues.append(f"Conflicting canonical tags across variants: {canonical_tags}")
# 2. Check if both www and non-www redirect to the same final URL
if not canonical_url:
final_urls = {v["final_url"] for v in https_variants.values()
if v["final_url"]}
if len(final_urls) == 1:
canonical_url = final_urls.pop()
confidence = "high"
issues.append("Both www/non-www converge on the same HTTPS URL via redirect.")
elif len(final_urls) == 2:
# Both are live and independent — problem!
issues.append(
"www and non-www are BOTH accessible without redirecting to each other."
)
issues.append(" This is a duplicate content risk for SEO!")
# Pick the one with a canonical tag, or the HTTPS non-www as convention
if https_nwww["canonical_tag"]:
canonical_url = https_nwww["canonical_tag"]
confidence = "medium"
elif https_www["canonical_tag"]:
canonical_url = https_www["canonical_tag"]
confidence = "medium"
else:
# Convention: prefer non-www HTTPS
canonical_url = https_nwww["final_url"] or https_www["final_url"]
confidence = "low"
# 3. Fall back to HTTP variants if HTTPS not available
if not canonical_url:
http_finals = {v["final_url"] for v in [http_nwww, http_www]
if v["final_url"]}
if http_finals:
canonical_url = http_finals.pop()
confidence = "low"
issues.append("No working HTTPS found — falling back to HTTP.")
# 4. Redirect chain health
for key, v in results.items():
if v["redirects"] > 3:
issues.append(
f"Long redirect chain ({v['redirects']} hops) on {v['url']}"
)
if v["error"]:
issues.append(f" Error on {v['url']}: {v['error']}")
# 5. HTTP -> HTTPS check
for http_key, https_key in [("http_non_www", "https_non_www"),
("http_www", "https_www")]:
h = results[http_key]
if h["final_url"] and h["final_url"].startswith("http://"):
issues.append(
f"{h['url']} does NOT redirect to HTTPS (lands on {h['final_url']})"
)
# 6. www <-> non-www cross-redirect check
nwww_final = https_nwww.get("final_url", "") or ""
www_final = https_www.get("final_url", "") or ""
def strip_trailing(u):
return u.rstrip("/")
if strip_trailing(nwww_final) == strip_trailing(www_final) and nwww_final:
pass # Good, they converge
elif nwww_final and www_final:
nwww_parsed = urlparse(nwww_final)
www_parsed = urlparse(www_final)
same_host = nwww_parsed.netloc == www_parsed.netloc
if not same_host:
issues.append(
"www and non-www resolve to DIFFERENT hosts — "
f"({nwww_parsed.netloc} vs {www_parsed.netloc})"
)
return {
"canonical_url": canonical_url,
"confidence": confidence,
"issues": issues,
}
# ── Output helpers ──────────────────────────────────────────────────────────
COLORS = {
"reset": "\033[0m",
"bold": "\033[1m",
"green": "\033[32m",
"yellow": "\033[33m",
"red": "\033[31m",
"cyan": "\033[36m",
"grey": "\033[90m",
}
def c(text, color):
return f"{COLORS[color]}{text}{COLORS['reset']}"
def print_result(data: dict, index: int, total: int):
domain = data["domain"]
verdict = data["verdict"]
variants = data["variants"]
conf_color = {"high": "green", "medium": "yellow", "low": "red", "unknown": "grey"}
color = conf_color.get(verdict["confidence"], "grey")
print(f"\n{c(f'[{index}/{total}]', 'grey')} {c(domain, 'bold')}")
print(f" {'Canonical URL':<18} {c(verdict['canonical_url'] or 'N/A', color)}")
print(f" {'Confidence':<18} {c(verdict['confidence'].upper(), color)}")
# Variant summary table
print(f" {c('Variant', 'grey'):<28} {c('Status', 'grey'):<10} {c('Final URL', 'grey')}")
for key, v in variants.items():
status = str(v["status_code"]) if v["status_code"] else "ERR"
sc = "green" if status == "200" else "red" if status == "ERR" else "yellow"
final = v["final_url"] or v["error"] or "-"
# Truncate long URLs
if len(final) > 60:
final = final[:57] + "..."
print(f" {c(v['url'], 'grey'):<40} {c(status, sc):<10} {final}")
# Issues
if verdict["issues"]:
for issue in verdict["issues"]:
ic = "yellow" if issue.startswith("") else "grey"
print(f" {c(issue, ic)}")
def write_csv(output_path: str, all_results: list):
with open(output_path, "w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow([
"domain", "canonical_url", "confidence",
"https_non_www_status", "https_non_www_final",
"https_www_status", "https_www_final",
"http_non_www_status", "http_non_www_final",
"http_www_status", "http_www_final",
"canonical_tag", "issues"
])
for data in all_results:
v = data["variants"]
verdict = data["verdict"]
# Collect any canonical tag found
tags = [v[k]["canonical_tag"] for k in v if v[k]["canonical_tag"]]
tag = tags if tags else ""
writer.writerow([
data["domain"],
verdict["canonical_url"] or "",
verdict["confidence"],
v["https_non_www"]["status_code"] or "",
v["https_non_www"]["final_url"] or v["https_non_www"]["error"] or "",
v["https_www"]["status_code"] or "",
v["https_www"]["final_url"] or v["https_www"]["error"] or "",
v["http_non_www"]["status_code"] or "",
v["http_non_www"]["final_url"] or v["http_non_www"]["error"] or "",
v["http_www"]["status_code"] or "",
v["http_www"]["final_url"] or v["http_www"]["error"] or "",
tag,
" | ".join(verdict["issues"]),
])
print(f"\n{c('checkmark', 'green')} Results saved to {c(output_path, 'cyan')}")
def write_txt(txt_path: str, all_results: list):
"""Write only the final canonical URL, one per line."""
with open(txt_path, "w", encoding="utf-8") as f:
for data in all_results:
url = data["verdict"]["canonical_url"] or ""
f.write(url + "\n")
print(f"{c('checkmark', 'green')} Canonical URLs saved to {c(txt_path, 'cyan')}")
# ── CLI entry point ─────────────────────────────────────────────────────────
def main():
parser = argparse.ArgumentParser(
description="Check canonical URLs for a list of domains."
)
parser.add_argument(
"--input", "-i", default="url.txt",
help="Input file with one domain per line (default: url.txt)"
)
parser.add_argument(
"--output", "-o", default="canonical_results.csv",
help="CSV output file (default: canonical_results.csv)"
)
parser.add_argument(
"--txt-output", "-x", default="canonical_results.txt",
help="Plain-text output file with one canonical URL per line (default: canonical_results.txt)"
)
parser.add_argument(
"--timeout", "-t", type=int, default=15,
help="Request timeout in seconds (default: 15)"
)
parser.add_argument(
"--delay", "-d", type=float, default=1.0,
help="Delay between domains in seconds (default: 1.0)"
)
args = parser.parse_args()
# Read domains
try:
with open(args.input, "r", encoding="utf-8") as f:
domains = [line.strip() for line in f if line.strip() and not line.startswith("#")]
except FileNotFoundError:
print(f"{c('Error:', 'red')} '{args.input}' not found.")
print(f"Create a file with one domain per line, e.g.:\n example.com\n www.mysite.org")
sys.exit(1)
if not domains:
print(f"{c('Error:', 'red')} No domains found in '{args.input}'.")
sys.exit(1)
total = len(domains)
print(c(f"\n Canonical URL Checker — {total} domain(s) to check\n", "bold"))
print(f" Input : {args.input}")
print(f" Output : {args.output} | {args.txt_output}")
print(f" Timeout: {args.timeout}s | Delay: {args.delay}s between domains")
all_results = []
with requests.Session() as session:
for i, domain in enumerate(domains, 1):
data = check_domain(domain, args.timeout, session)
all_results.append(data)
print_result(data, i, total)
if i < total:
time.sleep(args.delay)
# Summary
high = sum(1 for r in all_results if r["verdict"]["confidence"] == "high")
medium = sum(1 for r in all_results if r["verdict"]["confidence"] == "medium")
low = sum(1 for r in all_results if r["verdict"]["confidence"] == "low")
print(f"\n{'Summary':─<40}")
print(f" {c(str(high), 'green')} High confidence")
print(f" {c(str(medium), 'yellow')} Medium confidence (review recommended)")
print(f" {c(str(low), 'red')} Low confidence / errors (action needed)")
write_csv(args.output, all_results)
write_txt(args.txt_output, all_results)
if __name__ == "__main__":
main()
How the Script Works: A Section-by-Section Breakdown
Now let’s walk through the logic piece by piece, because understanding what the code does is more valuable than copy-pasting it.
Parsing Canonical Tags from HTML
The CanonicalParser class extends Python’s built-in HTMLParser. It scans the HTML response looking for a <link> tag whose rel attribute equals canonical, then stores the href value.
It is case-insensitive on the rel attribute, which matters because some CMS platforms output REL=”canonical” in uppercase.
class CanonicalParser(HTMLParser):
def __init__(self):
super().__init__()
self.canonical = None
def handle_starttag(self, tag, attrs):
if tag == "link":
attr_dict = dict(attrs)
if attr_dict.get("rel", "").lower() == "canonical":
self.canonical = attr_dict.get("href")
The parser only scans the first 50,000 characters of the response body, which is enough to cover any reasonable <head> section without downloading entire megabyte-sized pages in memory.
Canonical tags belong in <head>, and if a site has put one below 50KB of content, that is a separate problem entirely.
Fetching URLs and Following Redirects
The fetch() function handles one URL at a time. It uses a requests.Session (created once per run for connection reuse) and sets allow_redirects=True, so requests follows the entire chain automatically.
The function captures the redirect history, records the final URL, and passes the response body to CanonicalParser.
def fetch(url: str, timeout: int, session: requests.Session):
try:
resp = session.get(url, timeout=timeout, headers=HEADERS, allow_redirects=True)
chain = [r.url for r in resp.history] + [resp.url]
parser = CanonicalParser()
parser.feed(resp.text[:50_000])
return resp.url, resp.status_code, chain, parser.canonical, None
except requests.exceptions.SSLError as e:
return None, None, [], None, f"SSL error: {e}"
except requests.exceptions.ConnectionError as e:
return None, None, [], None, f"Connection error: {e}"
except requests.exceptions.Timeout:
return None, None, [], None, "Timeout"
except Exception as e:
return None, None, [], None, str(e)
The function returns a five-element tuple: final URL, status code, redirect chain, canonical tag value, and error string.
Any one of those can be None depending on what happened.
SSL errors and connection errors are caught separately so the output can give you a specific reason rather than a generic failure message.
This kind of explicit error handling is the same pattern covered in the web scraping with HTTPX guide, adapted here for requests.
Building and Checking All Four Variants
check_domain() normalizes the input domain, builds all four URL variants, and calls fetch() on each.
A 0.3-second delay sits between each variant request.
That is politeness, not performance.
You are hitting the same server four times in quick succession, and a small sleep reduces the chance of triggering rate limits or looking like an automated scan.
def check_domain(domain: str, timeout: int, session: requests.Session) -> dict:
bare = normalize_domain(domain)
has_www = bare.startswith("www.")
non_www = bare[4:] if has_www else bare
www_ver = "www." + non_www
variants = {
"https_non_www": f"https://{non_www}",
"https_www": f"https://{www_ver}",
"http_non_www": f"http://{non_www}",
"http_www": f"http://{www_ver}",
}
results = {}
for key, url in variants.items():
final, code, chain, canonical_tag, error = fetch(url, timeout, session)
results[key] = {
"url": url,
"final_url": final,
"status_code": code,
"redirect_chain": chain,
"canonical_tag": canonical_tag,
"error": error,
"redirects": len(chain) - 1 if chain else 0,
}
time.sleep(0.3)
verdict = determine_canonical(domain, results)
return {"domain": domain, "variants": results, "verdict": verdict}
The normalize_domain() function strips any protocol prefix the user might have included in url.txt, and removes trailing slashes. This means the input file can contain example.com, https://example.com, or www.example.com and the script handles all of them correctly.
Determining the Canonical URL
This is the core of the script. determine_canonical() applies six checks in priority order to decide which URL is canonical and how confident it is in that decision.
Priority 1:
Canonical tag. If a <link rel="canonical"> tag is found and all working variants point to the same canonical URL, confidence is high.
If different variants return conflicting canonical tags, confidence drops to low and the conflict is logged as an issue. Conflicting canonical tags are a real problem: they signal that different versions of a page are claiming different authoritative URLs.
Priority 2:
Convergence via redirect. If both https://example.com and https://www.example.com redirect to the same final URL, that URL is canonical and confidence is high.
This is the second-best signal after an explicit canonical tag.
Priority 3:
Both versions are live and independent. If both the www and non-www HTTPS versions return 200 without redirecting to each other, that is a duplicate content issue.
The script flags it as a problem, tries to infer a canonical from any available tag, and falls back to preferring non-www HTTPS by convention. Confidence is medium if a tag helps, low if not.
Priority 4:
HTTP fallback. If no HTTPS variant works at all, the script falls back to HTTP and marks confidence as low.
No working HTTPS is itself an issue worth flagging.
Checks 5 and 6: Redirect chain health
The script separately checks whether HTTP variants redirect to HTTPS (flagging those that stay on HTTP), whether redirect chains exceed three hops (which Google considers slow and inefficient), and whether www and non-www resolve to entirely different hostnames.
# Simplified excerpt from determine_canonical()
canonical_tags = {v["canonical_tag"] for v in working.values() if v["canonical_tag"]}
if len(canonical_tags) == 1:
canonical_url = canonical_tags.pop()
confidence = "high"
issues.append("Canonical tag present and consistent.")
elif len(canonical_tags) > 1:
confidence = "low"
issues.append(f"Conflicting canonical tags across variants: {canonical_tags}")
The confidence levels map directly to what action you should take: high means the canonical is probably correct and no immediate action is needed; medium means review it; low means fix it.
Output: Terminal, CSV, and Plain Text
The script writes results to three places simultaneously. The terminal gets color-coded output using ANSI escape codes: green for high confidence, yellow for medium, red for low.
The CSV output includes all variant data in a flat format suitable for spreadsheet analysis or importing into a reporting tool.
The plain text output is one canonical URL per line, which is useful if you want to pipe the results into another script.
The CSV columns are: domain, canonical_url, confidence, status codes and final URLs for all four variants, the canonical tag value if found, and a pipe-separated issues string.
If you are working with multiple output files as part of a larger automation pipeline, the running Python scripts in the background on Linux post covers how to detach long-running scripts from the terminal so a large domain list does not tie up your session.
Running the Python Canonical URL Checker Script
Basic run with default settings (reads url.txt, writes to canonical_results.csv and canonical_results.txt):
python check_canonical.py
Custom input file and output location:
python check_canonical.py --input my_domains.txt --output audit.csv
Adjust timeout and delay for slow or rate-limited servers:
python check_canonical.py --timeout 30 --delay 2.0
All arguments at once:
python check_canonical.py \
--input domains.txt \
--output results.csv \
--txt-output canonical_list.txt \
--timeout 20 \
--delay 1.5
The short-form flags are -i, -o, -x, -t, and -d respectively if you prefer brevity.
Understanding the Terminal Output
For each domain the script processes, you get a block like this:
[1/5] example.com
Canonical URL https://example.com
Confidence HIGH
Variant Status Final URL
https://example.com 200 https://example.com
https://www.example.com 200 https://example.com
http://example.com 200 https://example.com
http://www.example.com 200 https://example.com
Canonical tag present and consistent.
That is a clean result. All four variants converge on the same URL, the canonical tag confirms it, confidence is high.
A problematic result looks more like this:
[3/5] badsite.com
Canonical URL https://badsite.com
Confidence LOW
Variant Status Final URL
https://badsite.com 200 https://badsite.com
https://www.badsite.com 200 https://www.badsite.com
http://badsite.com 200 http://badsite.com
http://www.badsite.com 200 http://www.badsite.com
www and non-www are BOTH accessible without redirecting to each other.
This is a duplicate content risk for SEO!
badsite.com does NOT redirect to HTTPS (lands on http://badsite.com)
That site has three issues at once: duplicate www/non-www versions, no HTTPS redirect, and low confidence. Each one is an SEO problem that needs fixing before rankings stabilize.
Understanding the redirect issue in this output connects directly to how JSON responses and data structures work when you are parsing and processing URL data — the how to parse JSON in Python post is worth reading if you plan to extend the script to handle API-based URL data sources.
Extending the Python Canonical URL Checker Script
The script is intentionally structured so that each piece is replaceable. A few extensions worth considering:
Add concurrency. Right now the script processes domains sequentially.
For large lists, wrapping check_domain() with concurrent.futures.ThreadPoolExecutor would cut runtime significantly.
Keep the inter-request delay inside fetch() to avoid hammering individual servers.
For building more complex concurrent scraping logic, Python Automation With Selenium covers browser-level automation patterns that complement this kind of HTTP-only checker.
Integrate with a sitemap. If you want to check canonical consistency across all pages of a single site rather than just the root domain, you can feed the script URLs parsed from an XML sitemap.
The create an XML sitemap with Python post covers both generating and parsing sitemap files, which pairs cleanly with this checker.
Wrap it in a REST API. If you need this as a service rather than a CLI tool, the FastAPI tutorial shows how to turn a Python function like check_domain() into a proper HTTP endpoint in under an hour.
You could expose a /check route that accepts a domain name and returns the verdict as JSON.
Export to Google Sheets. The CSV output from write_csv() can be imported directly into Google Sheets for client reporting.
Alternatively, the gspread library lets you write directly to a sheet from Python, turning the script into a one-command audit report generator.
Common Issues and What They Mean for SEO
www and non-www both return 200 without redirecting. This is the most common and damaging canonical mistake.
Google may index both versions as separate pages, splitting the link equity between them. Fix: set a 301 redirect from one version to the other at the server or DNS level, then add a canonical tag on the target version as a belt-and-suspenders confirmation.
HTTP not redirecting to HTTPS. Google has used HTTPS as a ranking signal since 2014.
A site that still serves HTTP without redirecting is leaving a ranking signal on the table, and also making users less secure.
Fix: configure a 301 redirect from all HTTP variants to the HTTPS equivalent at the web server level.
Long redirect chains (more than 3 hops). Each hop in a redirect chain adds latency and costs a small amount of PageRank.
A chain like http://www.example.com → https://www.example.com → https://example.com → https://example.com/en/ is four hops where one would do.
Fix: collapse redirect chains to a single 301 wherever possible.
Conflicting canonical tags. This happens most often on sites that have migrated domains, changed URL structures, or have multiple plugins or themes generating their own canonical tags.
Fix: audit which system is outputting the tag and ensure only one wins, pointing to the correct URL.
SSL errors. An SSL error during fetching usually means an expired certificate, a certificate that does not cover www or non-www, or a misconfigured TLS setup.
Fix: renew or reissue the certificate and ensure it covers all variants you intend to serve.
Frequently Asked Questions (FAQs)
Can the script handle subdomains like blog.example.com?
Yes. If you put blog.example.com in your input file, the script constructs the four variants using that as the base: https://blog.example.com, https://www.blog.example.com, and the HTTP equivalents.
Most subdomains will not have a www.blog.example.com variant, so those checks will likely return errors, which the script records correctly.
What does a "medium" confidence result actually mean?
Medium confidence means the script found at least one signal pointing to a canonical URL, but also found a conflict or ambiguity. Usually this is a case where the www and non-www versions both live independently, but one of them has a canonical tag that points somewhere useful.
The verdict is technically a guess at that point. Review the issues list for the domain and fix whatever is causing the ambiguity.


