Google Search Engine Results Pages (SERPs) contain a wealth of valuable data for businesses and researchers. Accessing this information efficiently and at scale can be challenging, but tools and services like SerpApi offer a solution.
By simplifying the process of scraping Google SERPs (or any other search engines for instance), SerpApi enables users like us to extract vital insights without the complexities of traditional web scraping methods.
This powerful API opens up possibilities for in-depth data analysis, competitive intelligence, and market research, especially for SEO wizards.
However, to harness its full potential, users must understand the fundamentals of SerpApi and how to implement it effectively in their projects.
TL;DR
Hide- Create a SerpApi account to obtain an API key for accessing Google SERP data.
- Install the SerpApi Python client library using pip and configure your API key.
- Define search parameters like keywords and location to retrieve specific SERP data.
- Make API calls using the SerpApiClient to fetch JSON results from Google SERPs.
- Parse the JSON response to extract relevant information such as organic results or featured snippets.
Google SERPs and the Power of SerpApi
Web scraping has become a crucial skill for extracting valuable data from search engines like Google. However, scraping Google directly can be complex due to its anti-scraping policies and the need to handle constantly changing page structures.
Fortunately, SerpApi provides a reliable and legal solution for scraping Google Search Engine Results Pages (SERPs). In this guide, we’ll cover how to use SerpApi to scrape Google search results using Python.
SerpApi is an API service that allows you to get real-time search results from Google and other search engines without worrying about handling proxies, captchas, or changing HTML structures.
Structure of Google Search Results
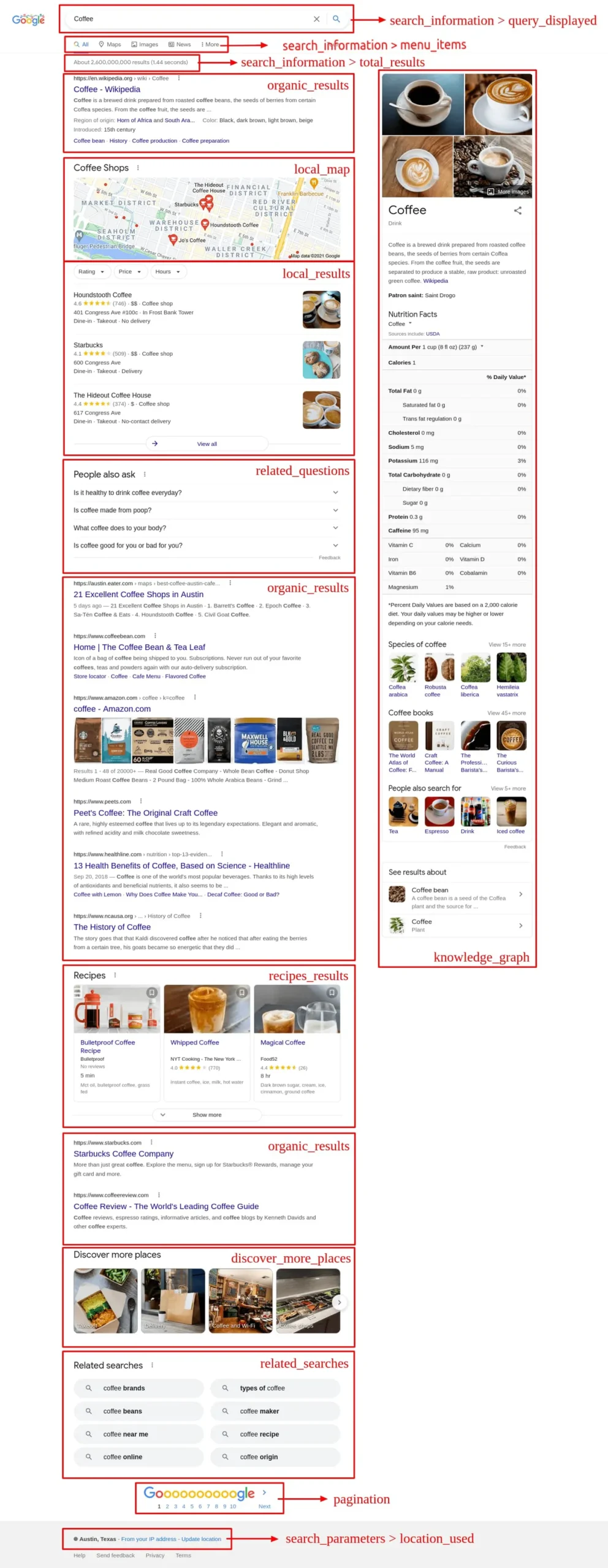
Google Search Engine Results Pages (SERPs) comprise various components, including organic results, local listings, paid advertisements, and many more.
 Source: SerpApi
Source: SerpApi
The structure also incorporates knowledge graphs and direct answer boxes, which provide immediate information for specific queries. Understanding these elements is vital for effectively utilizing SerpApi to extract and analyze valuable data from Google search results.
Organic, Local, and Ad Results
Search engine results pages (SERPs) comprise three primary components: organic results, local results, and ad results.
These elements form the core structure of Google search pages, providing users with diverse information sources.
- Organic results: Non-paid listings ranked by relevance
- Local results: Geographically targeted listings for nearby businesses
- Ad results: Paid listings displayed at the top or bottom of SERPs
- Knowledge panels: Information boxes providing quick answers
Understanding these components is vital for effective SERP scraping and data analysis.
Knowledge Graphs and Direct Answer Boxes
Two key components that enhance the user experience and provide quick access to information in Google SERPs are knowledge graphs and direct answer boxes. These elements offer concise, structured data to users, often eliminating the need to click through to websites.
| Feature | Purpose | Data Type |
|---|---|---|
| Knowledge Graph | Entity information | Structured |
| Direct Answer Box | Quick answers | Condensed |
| Featured Snippet | Top-ranking content | Extracted |
SerpApi enables efficient extraction of these valuable SERP components, empowering innovative data-driven strategies for businesses and researchers.
What is SerpApi?
SerpApi is a real-time search engine scraping API that provides structured results for search queries from various platforms like Google, Bing, Baidu, DuckDuckGo, and more.
Its primary advantage is that it handles challenges like captchas, IP blocks, and HTML structure changes on your behalf. Using SerpApi ensures your search result scraping stays within legal bounds by using an API-based solution.
Why I Choose SerpApi for Google SERP Scraping
I chose SerpApi for Google search results scraping because it simplifies the data collection process, and it offers 100 free searches per month.
Instead of manually coding or maintaining complex scripts by adding proxies or anti-captcha functions here and there, SerpApi’s easy-to-use API allows users to focus on their main goals: scrape the SERPs.
Using a dedicated search results API like SerpApi has several advantages when dealing with the complexity of Google’s search results pages:
- Eliminates manual data gathering, saving time and resources
- Provides real-time, accurate search result data
- Supports large-scale data extraction for thorough analysis
- Integrates easily with existing systems and workflows
SerpApi automates web scraping tasks, handling everything from HTTP requests to parsing HTML into JSON format, without requiring users to create or maintain custom scripts.
Its reliable infrastructure and built-in proxy system ensure consistent, high-quality results while avoiding detection by Google. This allows businesses to concentrate on strategically leveraging the data rather than dealing with technical challenges.
Benefits of Using SerpApi in Google SERPs Scraping for SEO
Using SerpApi to scrape Google Search Engine Results Pages (SERPs) offers several key advantages, especially for Search Engine Optimization (SEO) professionals. Let’s explore the main benefits:
1. Legal and Ethical SERP Scraping
One of the biggest challenges in traditional web scraping is staying within legal boundaries, particularly with services like Google, which implement aggressive anti-scraping measures.
SerpApi offers a legitimate, API-based solution that ensures you aren’t violating Google’s terms of service, allowing you to scrape SERPs ethically and securely without worrying about legal consequences.
2. Handling CAPTCHA and Proxies Automatically
Google often uses CAPTCHAs and blocks suspicious activity, such as frequent requests from the same IP address.
If you scrape directly without a tool like SerpApi, you must manage rotating proxies, deal with blocked IP addresses, and solve captchas manually or with third-party services.
With SerpApi, you don’t need to manage:
- Proxies: SerpApi handles proxy rotation for you.
- CAPTCHAs: Solving Google CAPTCHAs is built into the API.
This ensures that you receive uninterrupted access to SERP data, even for large-scale scraping.
3. Real-Time and Accurate Data for SEO Analysis
SEO is all about real-time data. Rankings fluctuate, and insights from stale data can lead to poor decision-making.
SerpApi provides real-time search results from Google, allowing SEO professionals to track the latest keyword rankings, discover competitor strategies, and monitor trends in organic search.
With SerpApi, you can track:
- Keyword performance across different regions and languages.
- Competitor rankings and pages.
- Featured snippets and rich results, such as knowledge panels and featured boxes.
4. Structured Data for Easier Parsing and Analysis
Traditional web scraping requires you to deal with HTML parsing, which can change frequently.
For Google SERPs, this can be especially challenging, as Google’s HTML structure often varies depending on query types and user locations.
SerpApi returns well-structured JSON data, which simplifies the process of extracting:
- Organic search results (title, URL, snippet).
- Paid ads data (if present).
- Featured snippets, image boxes, and local packs.
For SEO experts, this structured data allows for easier integration into automated workflows for tracking, analysis, and reporting.
5. Geotargeted SEO Insights
SEO is highly location-dependent, with rankings varying by country, city, or even by a specific neighborhood.
SerpApi allows you to target searches based on location with the location parameter.
For example, you can analyze how your website performs in different regions, allowing for more precise local SEO strategies:
- Monitor keyword performance across specific countries, cities, or even postal codes.
- Gather insights into localized search trends and competition.
- Track how your business appears in Google’s Local Pack results, especially for brick-and-mortar SEO.
6. Multiple Search Engines in One API
Although Google is the most prominent search engine, SEO professionals may also want to track rankings on other platforms. SerpApi supports multiple search engines, including:
- Bing
- Yahoo
- DuckDuckGo
- Baidu
This multi-platform support enables comprehensive SEO reporting across all major search engines, giving businesses a more complete picture of their organic search visibility.
7. Scalable for Large SEO Projects
For large-scale SEO campaigns, scraping thousands of SERPs regularly can be a nightmare if done manually or using direct web scraping methods.
SerpApi makes scaling easier by handling large volumes of requests. Whether you are tracking 100 keywords or 100,000, SerpApi ensures:
- Fast response times with robust rate limits.
- Automated pagination to scrape multiple pages of results.
8. Automated SEO Reporting and Monitoring
The ability to programmatically access real-time SERP data allows SEO professionals to build automated SEO reports and monitoring systems.
By integrating SerpApi into a Python-based tool, you can automate:
- Daily or weekly ranking reports for specific keywords.
- Competitor analysis by regularly fetching competitor positions.
- SERP feature monitoring for rich results like featured snippets, knowledge graphs, or image packs.
Automating SEO tasks with SerpApi reduces manual effort and provides accurate, timely insights that drive informed decision-making.
9. Consistent and Reliable Results
Manual scraping can lead to inconsistencies, especially when dealing with Google’s complex and dynamic SERP layouts. With SerpApi, you receive:
- Consistent and reliable data, even for complex query types.
- Regular updates and support, ensuring the API keeps working smoothly as Google’s algorithms and SERP layouts evolve.
This consistency is invaluable for long-term SEO strategies, where maintaining an accurate and continuous data feed is critical.
For SEO professionals, scraping Google SERPs is an essential task, but it can be technically challenging and fraught with legal risks when done directly.
SerpApi offers a reliable and effective answer to these issues. It streamlines the entire data collection process by providing organized, up-to-date information, managing captchas and proxies, and allowing us to concentrate on the important aspects: improving our SEO strategy with precise, valuable data.
For tasks such as keyword analysis, position monitoring, or observing rival companies, SerpApi provides a flexible, straightforward method to obtain Google search results data in Python.
Getting Started with SerpApi
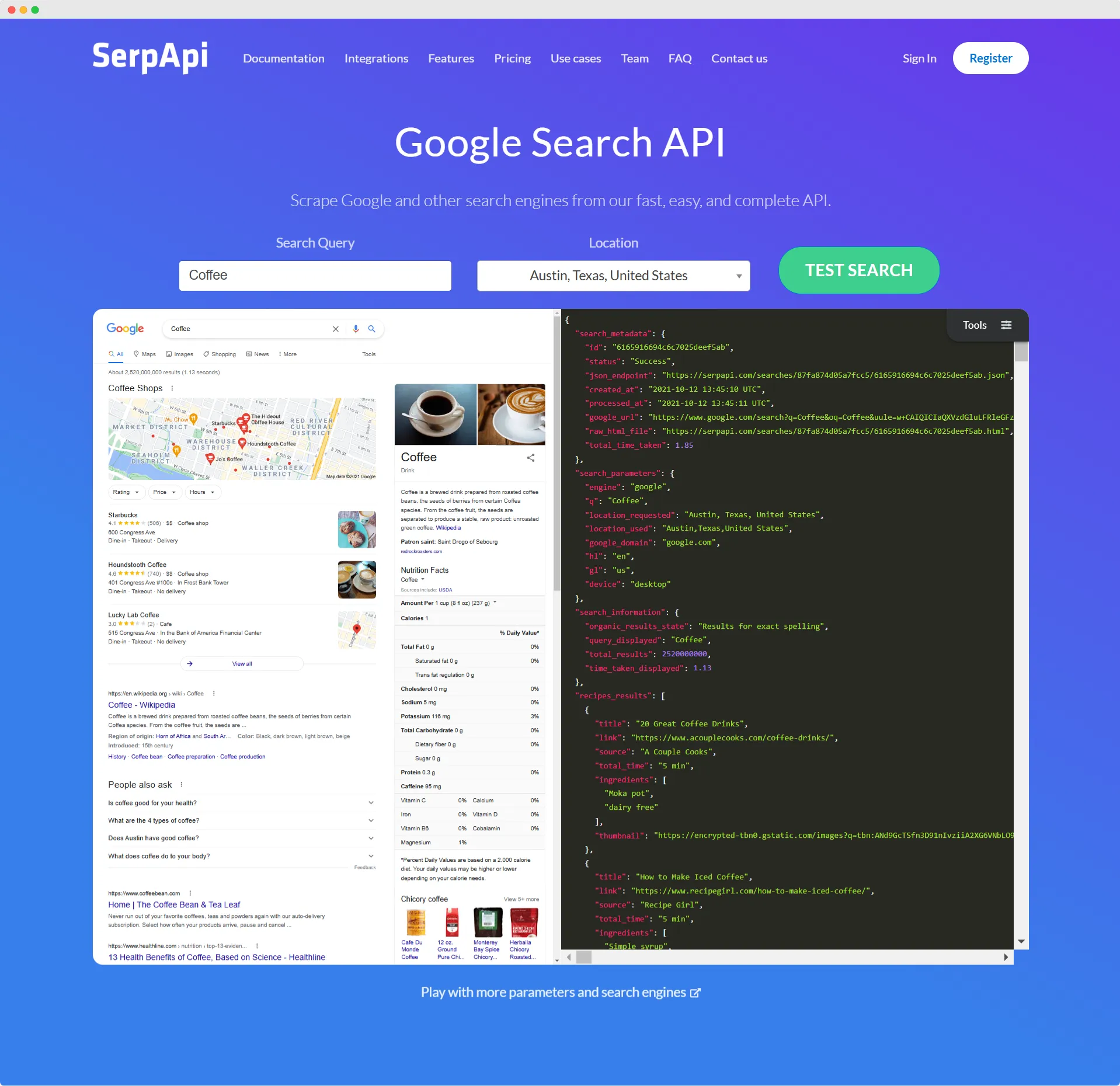
To begin using SerpApi for Google SERP scraping, the first step is to create a SerpApi account.
Once registered, users can access their dashboard to obtain their unique API key, which is essential for authenticating requests to the SerpApi service.
This API key enables users to make up to 100 API requests per month with a free account, while paid plans offer higher limits for more extensive scraping needs.
Creating the SerpApi Account
To begin using SerpApi for Google SERP scraping, users must create an account on the SerpApi website.
A free account provides up to 100 API requests per month, suitable for small-scale projects or initial testing.
For larger projects or more frequent scraping needs, SerpApi offers various paid plans with higher API request limits and additional features.
Free Search Credits and Pricing Plans
Initiating the Google SERP scraping process typically begins with creating a SerpApi account.
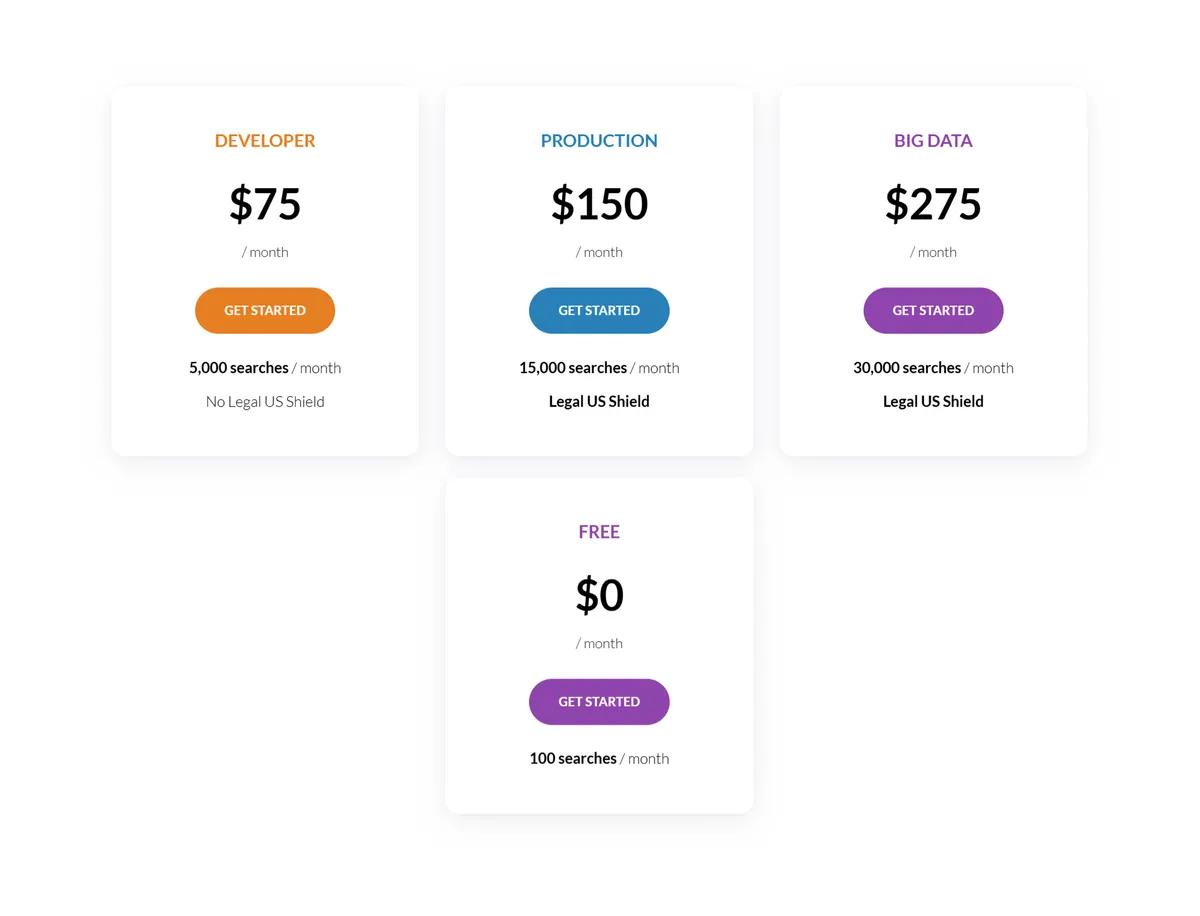
SerpApi offers a free tier and various pricing plans to accommodate different usage needs:
- Free tier: 100 searches/month
- Developer plan: 5,000 searches/month
- Production plan: 15,000 searches/month
- Big Data plan: 30,000 searches/month
Each plan provides access to SerpApi’s robust features, including real-time results, multiple search engines support, and advanced parsing capabilities. Production and Big Data plans are even included with Legal US shield to protect you from possible legal issue in the US.
Select the appropriate plan based on your project requirements and scalability needs.
For testing purpose, I’d go with the free tier plan. To see how good it is, I think 100 free searches per month is enough, then if we like what we get, we can always upgrade it, right?
Obtaining the SerpApi API Key
To access SerpApi’s functionality, users must obtain an API key, which serves as a unique identifier for their account.
This key is essential for authenticating API requests and tracking usage limits associated with the user’s plan.
Once acquired, the API key can be seamlessly integrated into code snippets or API calls, enabling users to leverage SerpApi’s capabilities for retrieving and analyzing Google search results.
Accessing SerpApi with the API Key
Accessing SerpApi with your unique API key is a crucial step in leveraging the platform’s capabilities for Google SERP scraping.
This process involves:
- Integrating the API key into your code
- Sending authenticated requests to SerpApi endpoints
- Configuring search parameters
- Handling API responses
Scraping Google SERPs with SerpApi Using Python: A Step-by-Step Guide
In this tutorial, we will explore how to utilize SerpApi with Python to efficiently retrieve current search results information from Google.
Prerequisites
Before we dive into the code, you’ll need the following:
- SerpApi Account: You need an account to access the API and get an API key.
- Python: Ensure Python 3.x is installed on your system.
- Python IDE: You can use any Python development environment or even a basic text editor.
- SerpApi Python SDK: This simplifies interacting with SerpApi.
Step-by-Step Guide: Scraping Google SERPs with SerpApi in Python
To begin scraping Google SERPs using Python, developers must first establish their development environment by installing the necessary libraries and dependencies.
Once the environment is configured, retrieving SERP data involves utilizing the SerpApi client library to make API calls and parse the returned JSON responses.
The extracted data can then be processed, analyzed, and stored according to the developer’s specific requirements, enabling efficient extraction of valuable information from Google search results.
Step 1: Setting Up the Python Environment
If you haven’t already, set up your Python environment. It’s advisable to create a Python virtual environment to manage dependencies:
python3 -m venv serpapi_env source serpapi_env/bin/activate
# For Windows, run: serpapi_env\Scripts\activateStep 2: SerpApi Python SDK Installation
Next, install the SerpApi Python SDK using pip:
pip install google-search-results
The google-search-results package provides methods to query SerpApi and parse results.
Step 3: Writing a Python Script to Fetch Google SERPs
Now that you have your API key and environment set up, you can write a Python script to scrape Google SERPs.
Here’s a basic example of how to use the SerpApi Python SDK to search Google:
from serpapi import GoogleSearch
# Insert your SerpApi API key here
API_KEY = 'your_serpapi_api_key_here'
def search_google(query):
# Prepare the search query parameters
params = {
"engine": "google", # Search engine
"q": query, # Search query
"api_key": API_KEY, # Your SerpApi API key
"location": "United States" # Optional: Specify search location
}
# Create a search client
search = GoogleSearch(params)
# Perform the search and get results
results = search.get_dict()
# Print out the results
return results
# Perform a sample search
query = "Python web scraping"
search_results = search_google(query)
# Print the top results
for result in search_results['organic_results']:
print(f"Title: {result['title']}")
print(f"Link: {result['link']}\n")
Here’s the code explanation, part by part:
- GoogleSearch: This is the class from the SerpApi SDK used to initiate a search.
- params: These are the parameters passed to the search engine. The most important parameters are:
- engine: This specifies which search engine to use. In our case, it’s
"google". - q: The search query string.
- api_key: Your SerpApi API key.
- location: Optionally, you can specify the location for region-specific search results.
- engine: This specifies which search engine to use. In our case, it’s
- get_dict(): This method executes the search and returns the results in JSON format as a dictionary.
Step 4: Parsing and Extracting Data from Results
Once you get the search results, you need to parse the dictionary to extract relevant data. SerpApi returns results in a structured format, making it easier to extract specific elements such as titles, links, snippets, etc.
In the code example above, we iterate through the "organic_results" list, which contains the actual search results.
for result in search_results['organic_results']:
print(f"Title: {result['title']}")
print(f"Link: {result['link']}\n")
Here’s an example output:
title: Python Web Scraping Tutorial %E2%80%93 Learn to Scrape WebsitesLink: https://www.example.com/python-web-scraping-tutorialTitle: Best Tools for Python Web ScrapingLink: https://www.example.com/best-python-scraping-toolsCustomizing the Search Query
You can further customize your search query by adding additional parameters. Here are a few useful ones:
- num: Number of search results to return (e.g.,
num=10for top 10 results). - location: Specify a region or city for geo-targeted results (e.g.,
"location": "New York"). - hl: Set the language of the results (e.g.,
"hl": "en"for English). - gl: Set the country of the results (e.g.,
"gl": "us"for United States).
For example, to get the top 5 results in French for a search query, you can modify the parameters:
params = {
"engine": "google",
"q": "Python web scraping",
"num": 5,
"hl": "fr",
"api_key": API_KEY
}
Pagination and Fetching Multiple Pages of Results
SerpApi makes it easy to paginate through search results by using the start parameter. You can specify the starting result index to fetch the next set of results.
Here’s an example to fetch the first 30 results (in sets of 10):
def search_google_pagination(query):
results = []
for start in range(0, 30, 10): # Fetch 3 pages (10 results per page)
params = {
"engine": "google",
"q": query,
"start": start,
"num": 10,
"api_key": API_KEY
}
search = GoogleSearch(params)
page_results = search.get_dict()
results.extend(page_results['organic_results'])
return results
# Perform a paginated search
query = "Python web scraping"
paginated_results = search_google_pagination(query)
# Print out the titles and links
for result in paginated_results:
print(f"Title: {result['title']}")
print(f"Link: {result['link']}\n")
This script retrieves three sets of search results (totaling 30 results) and merges them into a single list.
Error Handling and Rate Limits
SerpApi has a rate limit based on your subscription plan. It’s essential to handle potential errors such as exceeding the API call limit or network-related issues.
Here’s an example of how to handle errors:
from serpapi import GoogleSearch
import time
API_KEY = 'your_serpapi_api_key_here'
def search_google(query):
try:
params = {
"engine": "google",
"q": query,
"api_key": API_KEY,
}
search = GoogleSearch(params)
results = search.get_dict()
return results
except Exception as e:
print(f"Error occurred: {e}")
time.sleep(60) # Wait for 60 seconds before retrying
return None
SerpApi automatically returns a clear error message if you exceed the rate limit or send a malformed request.
Using SerpApi to scrape Google search results is a straightforward, efficient, and legal method to retrieve search engine data without dealing with the intricacies of captchas, proxies, or dynamic HTML.
By adhering to the steps in this guide, you can establish a robust SERP scraping tool in Python. Tailor the search query, manage pagination, and always consider rate limits to guarantee seamless and productive scraping.
SerpApi streamlines the process, enabling you to concentrate on extracting insights and analyzing information from Google search results without technical obstacles.
Best Practices and Legal Considerations
When engaging in web scraping activities, it is essential to adhere to ethical guidelines and respect website terms of service.
Implementing measures to avoid detection by search engines, such as using rotating IP addresses and mimicking human behavior, can help maintain the longevity of scraping operations.
Additionally, understanding and complying with legal considerations, including copyright laws and data protection regulations, is essential for responsible and sustainable web scraping practices.
Understanding Web Scraping Ethics
SerpApi’s Legal Shield offers protection for users engaging in web scraping activities.
This feature provides a layer of legal security, mitigating potential risks associated with data extraction from Google SERPs.
SerpApi’s Legal Shield
Web scraping ethics and legal considerations are crucial aspects of using SERP scraping tools like SerpApi.
The platform’s “Legal US Shield” provides a layer of protection for users, ensuring compliance with legal standards.
SerpApi’s approach includes:
- Mimicking human behavior to reduce detection risk
- Utilizing proxies for anonymity
- Adhering to website terms of service
- Respecting robots.txt files
This strategic implementation of ethical scraping practices enables users to innovate confidently while minimizing legal risks associated with data extraction from Google SERPs.
Avoiding Detection by Google
SerpApi employs advanced proxy technologies to mimic human behavior and reduce the risk of detection by Google’s anti-scraping measures.
These proxies rotate IP addresses and user agents, making it challenging for Google to identify automated requests. By utilizing SerpApi’s proxy infrastructure, users can conduct large-scale SERP scraping operations without triggering Google’s defense mechanisms, ensuring a higher success rate and more reliable data collection.
Using SerpApi’s Proxy Technologies
Proxy technologies form the backbone of SerpApi’s approach to avoiding detection by Google while scraping search results.
These advanced techniques guarantee reliable and uninterrupted data collection:
- Rotating IP addresses
- Mimicking human behavior patterns
- Implementing intelligent request throttling
- Utilizing geographically diverse server locations
Wrapping Up
Ultimately, SerpApi offers a robust solution for Google SERP scraping, streamlining data extraction and analysis processes.
Through utilizing the API’s capabilities, users can efficiently gather valuable search engine results data.
Adherence to best practices and legal considerations is vital when implementing SERP scraping strategies.
SerpApi’s scalable architecture and detailed documentation facilitate seamless integration into existing workflows, enabling organizations to make data-driven decisions based on accurate, real-time SERP information.


